
What is the computational speed of the PID algorithm?
In order to measure this, I will use GPIO PG2 as a flag that can be measured with my scope.
But first I will improve the placement of my variables. It is very annoying with STM32CubeMonitor if the linker places variables at different addresses after a compilation run. This could happen even after small code changes. Unfortunately, all the useful widgets like sliders and switches require using absolute addresses for writing variables. I hope that ST improves on that in the future!
Maybe the best remedy for this nuisance is to tell the linker to place the relevant variables into a specific section.
This can be done via an __attribute__ as described in UM2609 in chapter 2.5.7.3.:
/* USER CODE BEGIN PV */
__attribute__((section(".data"))) volatile float nominal = 0.5;
__attribute__((section(".data"))) volatile float d0 = 0.5;
__attribute__((section(".data"))) volatile float d1 = 0.1;
__attribute__((section(".data"))) volatile float d2 = 0.0;
__attribute__((section(".data"))) volatile int32_t regulator_ON = 0;
/* USER CODE END PV */
PG2 will be set as first line of code in ADC_IRQHandler(void) and it will be reset in the last line of code right before the return statement.
The screenshot of the scope shows the disturbance signal (light blue), the output signal (yellow) and PG2 (dark blue):
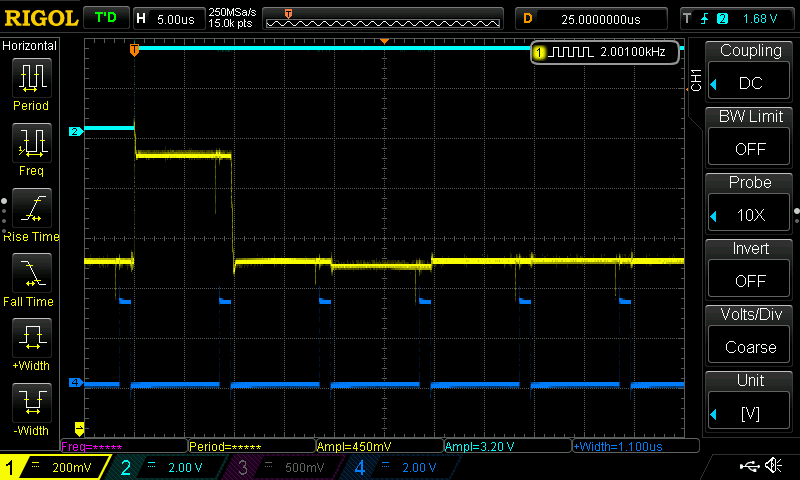
The exact duration of the PG2 is 1.164 µs which can be measured more exactly by means of a higher time resolution of 200 ns/div.
Up to now no optimization („-O0“) was used for the GCC compiler.
In order to speed up the ADC IRQ, I used another __attribute__, which I placed in front of the definition of the ADC IRQ handler function in stm32h7xx_it.c:
__attribute__((optimize("-Ofast"))) void ADC_IRQHandler(void)
{
/* USER CODE BEGIN ADC_IRQn 0 */
GPIOG->BSRR = (1 << 2); // output pulse ON for speed measurements
.
.
The result is impressive:
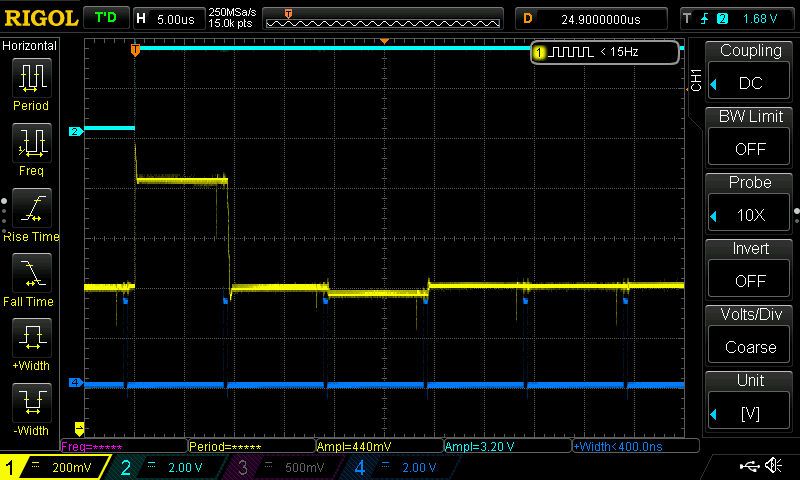
The computational speed improves from 1.164 µs to 398 ns!
It looks like using this __attribute__ has been really worth it!